|
|
HUBEI UNIVERSITY OF AUTOMOTIVE TECHNOLOGY

數據結構
課程設計報告
課設題目:
| | 專 業:
| | 班 級:
| | 姓 名:
| | 完成日期:
| | 指導教師:
| |
一.設計題目
Ø課程設計題目:多種查找方式的比較
Ø實現的功能:
1. 順序查找
2. 二分查找
3. 哈希查找
v順序查找
1. 隨機產生隨機數 2. 手動輸入產生隨機數 3. 建立線性表進行順序查找
v二分查找
1. 隨機產生隨機數 2. 對產生的隨機數進行冒泡排序(由大到小) 3. 進行二分查找
v哈希查找
1.手動輸入產生隨機數 2. 進行哈希查找
Ø各種查找的簡單介紹:
1> 順序查找
查找是在程序設計中最常用到的算法之一,假定要從n個整數中查找x的值是否存在,
最原始的辦法是從頭到尾逐個查找,這種查找的方法稱為順序查找。
順序查找的程序如下:
# include <stdio.h>
# define N 15
int main(void)
{
void bi_search(int a[],int n,int x);
int a[100];
int x, i;
int n = 15;
printf("input the numbers:\n");
for(i=0; i<n;i++ )
scanf("%d",&a)
printf("input x:\n");
scanf("%d", &x);
bi_search(a,n,x);
}
void bi_search(int a[], int n, int x)
{
int i = 0;
int find = 0;
while(i<n)
{
if(x==a)
{
printf("find:%3d,it is a[%d]",x,i);
printf("\n");
find = 1;
}
i++;
if(i!=find)
printf("%3d not been found!\n", x);
}
2> 二分查找
/* 當前查找區間R[low..high]非空,使用(low+high)/2會有整數溢出的問題,問題
會出現在當low+high的結果大于表達式結果類型所能表示的最大值時,這樣,產生
溢出后再/2是不會產生正確結果的,而low+((high-low)/2)不存在這個問題*/
int BinSearch(SeqList*R, int n, KeyType K)
{
/* 在有序表R[0..n-1]中進行二分查找,成功時返回結點的位置,失敗時返回-1 */
int low = 0, high = n-1, mid; /* 置當前查找區間上、下界的初值 */
while(low <= high)
{
if(R[low].key == K)
return low;
if(R[high].key == k)
return high;
mid = low+((high-low)/2);
if(R[mid].key == K)
return mid;//查找成功返回
if(R[mid].key > K)
high = mid-1;//繼續在R[low..mid-1]中查找
else
low = mid+1;//繼續在R[mid+1..high]中查找
}
if(low > high)
return-1;//當low>high時表示所查找區間內沒有結果,查找失敗
}
3> 哈希查找
① 常用的哈希函數構造方法有:
l直接定址法
l除留余數法
l乘余取整法
l數字分析法
l平方取中法
l折疊法
l隨機數法
② 本程序采用的是除留余數法:
Hash(key)=key mod p (p是一個整數)
2特點:以關鍵碼除以p的余數作為哈希地址。
2關鍵:如何選取合適的p?p選的不好,容易產生同義詞
2技巧:若設計的哈希表長為m,則一般取p≤m且為質數
(也可以是合數,但不能包含小于20的質因子)。
二.設計目的
通過此三種算法的比較,突出各自的優缺點:
順序查找過程:從表中的最后一個記錄開始,逐個進行記錄的關鍵字與給定值進行比較,若某個記錄的關鍵字與給定值相等,則查找成功,找到所查的記錄;反之,若直到第一個記錄,其關鍵字和給定值比較都不相等,則表明表中沒有所查的記錄,查找失敗。
算法描述為
int Search(int d,int a[],int n)
{
/*在數組a[]中查找等于D元素,若找到,則函數返回d在數組中的位置,否則為0。其中n為數組長度*/
int i ;
/*從后往前查找*/
for(i=n-1;a!=d;--i)
return i ;
/*如果找不到,則i為0*/
}
此算法在數據的復雜度比較小的時候比較方便和占有優勢,但當查找的數據量很龐大時,此算法就顯得有點不適用了。
二分查找又稱折半查找,它是一種效率較高的查找方法。
其流程圖如下:
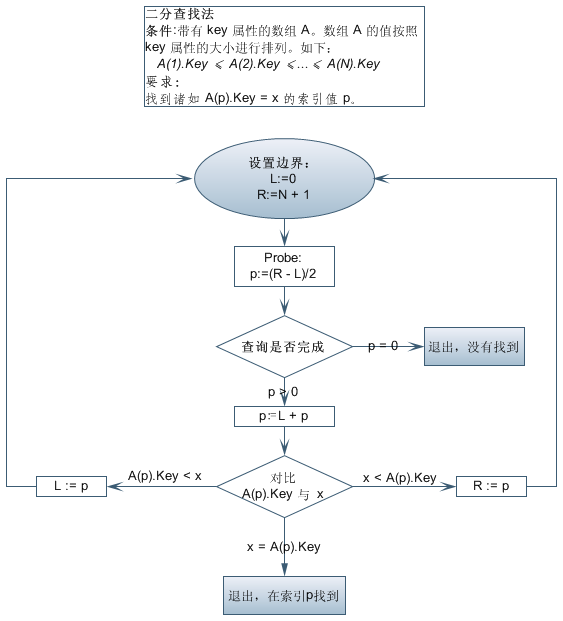
【二分查找要求】 1. 必須采用順序存儲結構 2. 必須按關鍵字大小有序排列。
【優 缺 點】 折半查找法的優點是比較次數少,查找速度快,平均性能好;其缺點是要求待查表為有序表,且插入刪除困難。因此,折半查找方法適用于不經常變動而查找頻繁的有序列表。
哈希查找
1. 基本原理
我們使用一個下標范圍比較大的數組來存儲元素。可以設計一個函數(哈希函數, 也叫做散列函數),使得每個元素的關鍵字都與一個函數值(即數組下標)相對應,于是用這個數組單元來存儲這個元素;也可以簡單的理解為,按照關鍵字為每一個元素"分類",然后將這個元素存儲在相應"類"所對應的地方。
但是,不能夠保證每個元素的關鍵字與函數值是一一對應的,因此極有可能出現對于不同的元素,卻計算出了相同的函數值,這樣就產生了"沖突",換句話說,就是把不同的元素分在了相同的"類"之中。后面我們將看到一種解決"沖突"的簡便做法。
總的來說,"直接定址"與"解決沖突"是哈希表的兩大特點。
2. 函數構造
構造函數的常用方法(下面為了敘述簡潔,設 h(k) 表示關鍵字為 k 的元素所對應的函數值):
a) 除余法:
選擇一個適當的正整數 p ,令 h(k ) = k mod p
這里, p 如果選取的是比較大的素數,效果比較好。而且此法非常容易實現,因此是最常用的方法。
三.總體設計
Ø程序框架圖:
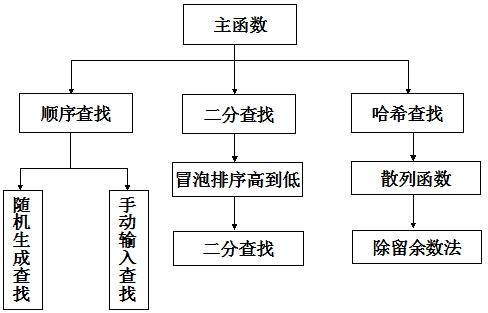
Ø函數調用流程圖:
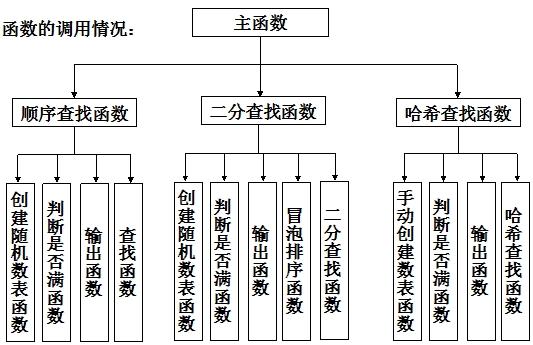
四.詳細設計步驟
1.搭建程序的整個框架
# include<stdio.h>
void printSeq();//隨機順序查找法
void printBin();//二分查找法
void hashtable();//哈希查找
int main(void)
{
return 0;
}
printSeq();//隨機順序查找法
{
}
printBin();//二分查找法
{
}
hashtable();//哈希查找
{
}
2.頭文件的添加
# include "iostream"
# include "stdlib.h"
# include "stdio.h"
# include <time.h>
# include "malloc.h"//動態內存分配的頭文件
3.定義相關的結構體數據類型
using namespace std;
typedef int ElemType; //ElemType類型為int類型 即ElemType等價于int
int size = 0; //哈希表的長度
4.相關參數的宏定義
# define maxsize 100
# define m 19 //m = 19
# define free 0 //free = 0
# define sucess 1 //sucess = 1
# define unsucess 0 //unsucess = 0
# define MAX 11 //MAX = 11
# define hm 20 //hm = 20
# define keytype int //keytype類型為int型
5.主函數中調用其它功能模塊的函數
6.寫出主函數中被調用的函數
üvoid printSeq()//隨機順序查找法
üvoid printBin()//二分查找法
üvoid hashtable()//哈希查找
üvoid Sort(SSTable *table )
üvoid stable create_s(stable r)
üvoid PrintTable(SSTable *table)
üvoid Destroy(SSTable *table)/* 函數:銷毀 */
üvoid FillTable(SSTable *table)/* 函數:判斷是否已滿 */
üvoid Create(SSTable **table, int length)/* 創建 */
üvoid hashcreate(hashtable ht[], keytype key)
üvoid search_shoudong()//隨機順序手動查找法
üint show()
üint search_s(keytype k,stable *r)
üint HashFunction(keytype key)/*散列函數*/
üint hashsearch(hashtable ht[], keytype key)
üint Search_Bin(SSTable *table, ElemType key)
üint Search_Seq(SSTable *table, ElemType key)/* 函數:查找 */
7.先寫出相關被調函數的偽代碼
舉例:判斷建立的時間表是否已滿
If(時間表長度為滿)
Printf(“創建失敗!\n”);
else
Printf(“創建成功!\n”);
8.用C或C++……等語言將偽代碼描述出來
9.若被調函數放在主函數之后,則要進行函數的聲明;相反則不需要
10.進行程序的簡單調試及修改
11.對用戶的違法輸入的操作的調試及修改
12.進一步的對程序中的bug進行調試及修改
13.功能的進一步擴充及完善
五.設計結果與分析
1)設計的運行結果
2運行菜單的主界面:
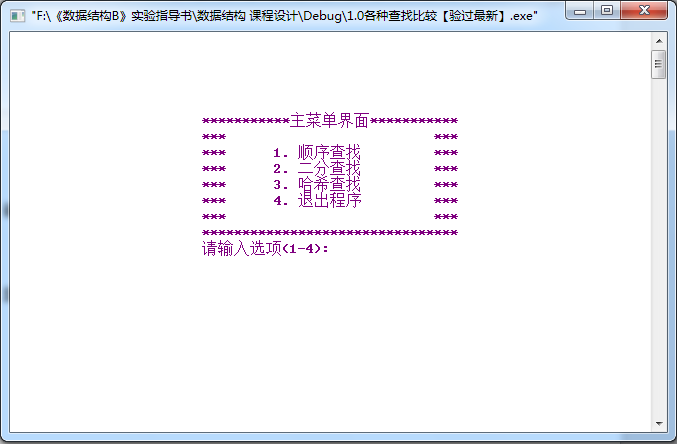
2順序查找界面:
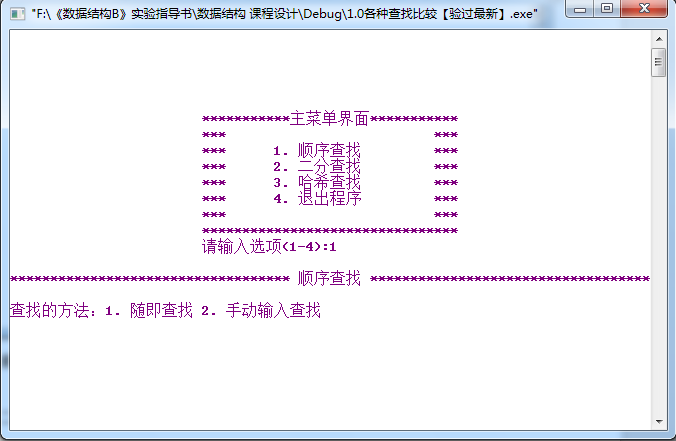
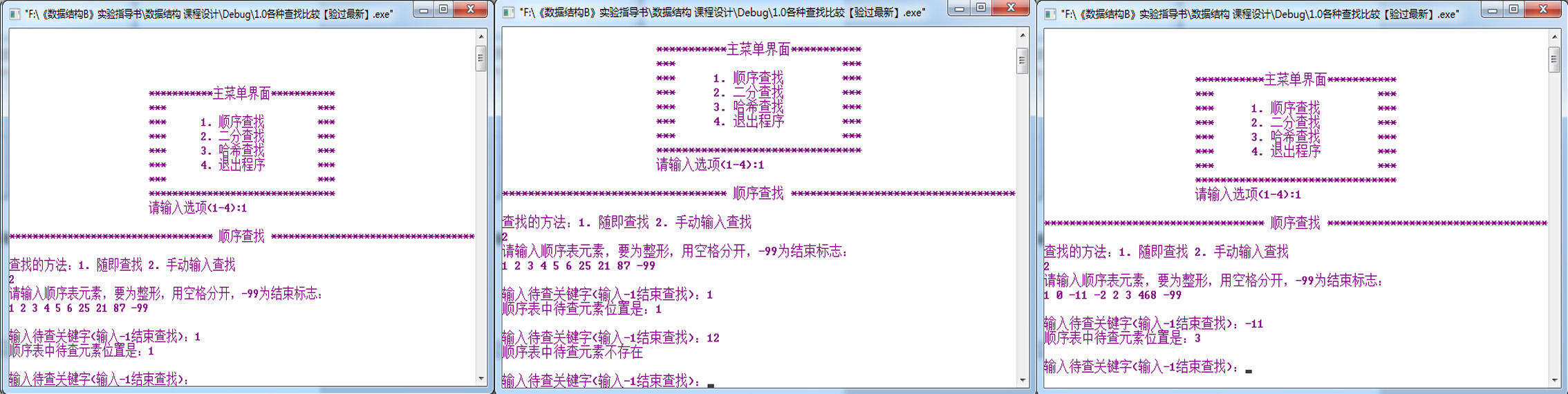
u順序隨機查找的三種調試結果:

u順序手動輸入查找的三種調試結果:
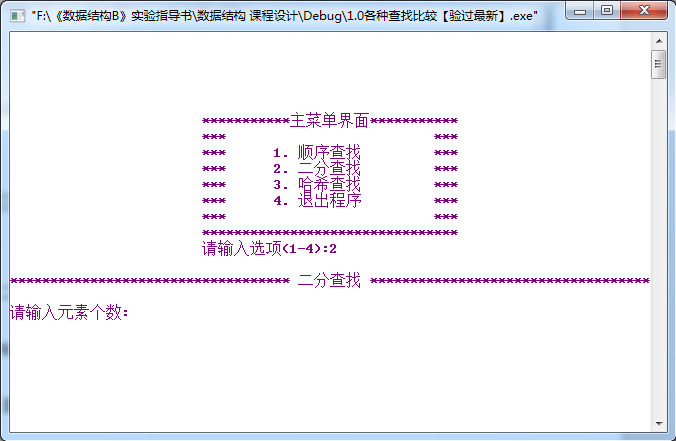
2二分查找界面:
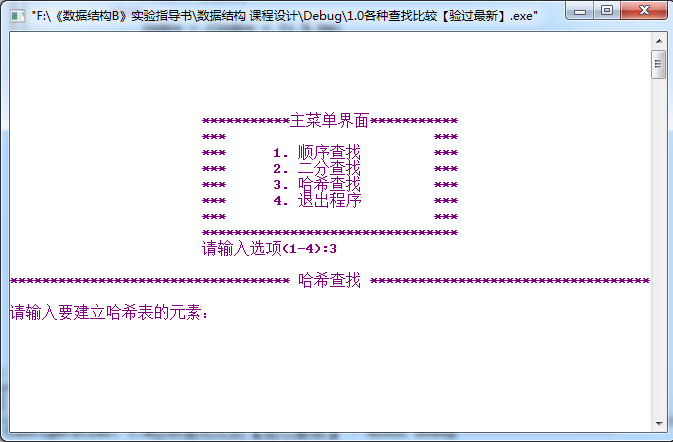
2哈希查找界面:
2) 調試分析
l調試時注意哪些問題
1. 除了輸入的信息提示外還可以進行非法的輸入
2. 對垃圾的垃圾字符的回收
3. 注意緩沖和清屏
l如何去調試程序
1. 調試時具有隨機性和非法性輸入
2. 調試的結果不能太單一,如產生的隨機種子要有正、負數和零
l如何去修改程序的bug(漏洞)
1. 一個好的程序是調試出來的
2. 邊試邊調試不斷地修改
3. 通過非法或任意輸入來修改程序的漏洞
l如何去排除掉用戶的非法輸入
1. 對輸入的垃圾字符進行回收
2. 對相關的菜單界面進行緩沖和清屏
3. 調試程序時要全面,防止出現用戶的非法輸入
l如何去使自己的程序更全面
1. 不斷地調試和完善
2. 通過不同的用戶來調試反饋相關問題并完善之
3. 使程序更加精簡和通俗易懂
l找用戶進行調試來反饋問題
1. 這是一個產品進入市場前的一個關鍵步驟,如一款游戲或軟件會標注試用版,通
過用戶的試用來反饋一些問題
l進一步完善程序中的漏洞
[color=#ff0000,strength=3)"]六.總結(收獲和不足)
總結是對所學的知識的一種總結,是一種很好的學習方法,不管是現在的學習總結還是今后走向工作崗位時的工作總結都會讓自己受益匪淺。
通過多天的漫長學習,自己和組員終于完成了此課程設計,自己不斷是收獲了知識也收獲了團隊精神。
大的程序的開發周期都是很漫長的,長的會達兩年或兩年以上的開發期。所以一個人是無法完成這樣巨大的工作量的,必須靠一個團隊去完成。俗話說:“三個臭皮匠賽過諸葛亮”,這句話是很有道理的,自己的能力即使很強,也要靠團隊去完成。不過話說回來,現在的這種意識還不是很強,搞技術的很多人更多的是個人的抱負。希望自己能搞出點驚天動地的東西出來,但是要是在公司的話,這絕對是不允許的。因為公司開發一個產品的周期時間還有限的,需要一個團隊在最短的時間內去完成產品的設計。
從這次的數據結構的課程設計過程中深有體會,如何更好地去完成一個大的程序,就像開發一個大的軟件。得有明確的分工,所以我們要去了解程序的特點,其中函數和指針是很有用的東西,通過這些可以將很大的程序高效的完成。
這就像好比開發一個大的軟件,項目的負責人將程序的主框架搭好,定義一些全局變量,并,列舉出要調用的功能函數名稱,項目負責組只要完成主函數的調用很簡單的編寫。而那些功能函數模塊則交給下面那些程序員來分組完成。最后將所有的功能函數整合到一起。一個大的軟件的開發過程就完成的四分之一了。還有二分之一的時間是來調試錯誤和完善功能,所以說好的程序不是寫出來的而是調試出來的。所以我們小組三人在這次程序調試過程中實現了很好的分工,老師看完程序后要求進行三個功能方面的修改:1. 程序產生的隨機數是隨機的要包括正、負數和零。 2. 查找實現隨機查找和手動輸入查找。 3.對二分查找中的冒泡排序由低到高排序改為從高到低排序。 4. 完善哈希查找的功能。
我們小組進行了分工,每人完成一個功能的修改,最后整合到一個程序中。我們很快各自完成了自己的那塊,最后整合到了一起。當然由于能力的有限,小組對最后的哈希查找功能的完善沒有實現。最后在驗收的過程中還是通過了。
當然此次的課程設計走了很多彎路,在剛開始的時候沒有確定目標對象,所以導致了后面出現了兩個備案,兩個任務進行來回之間的切換,造成了時間的浪費。這是我們此次學習過程中吸取的一個教訓。
通過此次的課程設計,自己對數據結構的學習和理解又上升了一個層次,自己不斷地在進步。自己所希望對的就是要達到這個效果。
此次的學習讓自己意識到很多方面的不足,對哈希查找和二叉樹的相關知識還不夠熟悉,導致最后一個功能模塊沒能很好的完成,所以后面還需要不斷地學習。這門課程是計算機課程中的一門核心課程,學完后感覺眼界大開。
學完這門課程后,對函數的理解又上升了一個層次。原來在學習C語言時還不懂什么是函數,也不知道函數是用來干什么的。那時區分不清楚編程中的函數與數學中的函數有什么區別。所以當我們對一個東西不理解時,我們是無法去駕馭它的,更談不上去編寫出優秀的代碼。
學習編程是一個漫長的過程,從大一的文盲到現在的菜鳥是一種進步,是一個漫長的過程,也是一個漫長的積累。自己在這方面走了不少彎路,也下了不少功夫,但是效果不是很明顯。
在后面的學習過程中,這門課程的地位依然是顯得那么重要,后面的計算機課程、單片機學習課程是和數據結構的學習是離不開的。
說了這么還是說明了這門課程的重要性,要學好這門課程,不是一兩年就能搞定的,要不斷的運用到實踐中和反復的去理解和體會。
還有一點是:老師上課講的更多是偽代碼而不是實際程序,理解一個偽代碼幾分鐘就可以搞定,但是理解代碼的話不就那么簡單了。要把它寫出來更是難上加難了。所以不能停留在表面,程序必須要自己去寫和調試,這樣才能真正的理解和掌握,不然永遠都不可能寫出一手好的代碼。
通過數據結構的學習,自己對計算機的底層一些東西也是有了一些理解。如,偽代碼、編譯和鏈接等等。
“偽代碼”很明顯是假代碼的意思,它是由編譯器來識別的,計算機是不承認它的,因為計算機跑的只有“0”和“1”,這些偽代碼當然有它的作用,它會告訴編譯器從何處執行,執行到何處時該怎么辦。
所以通過數據結構的學習將前前后后的知識都穿插了起來,就像指針一樣。前前后后學習的知識是離散的,分布在大腦的各個部分,數據結構就好比這個指針,將它們前前后后串起來了。這是比較有意思的,似乎好多的東西和思想是相通的,不管是什么專業領域。可謂“萬變不離其宗”。
[color=#ff0000,strength=3)"]附源代碼:
/*
課題名稱:各種查找方法的比較
小組成員:曾奕云 袁能峰 汪一帆
時 間:2014年7月5日
*/
# include "iostream"
# include "stdlib.h"
# include "stdio.h"
# include "malloc.h"//動態內存分配的頭文件
# define MAX 11 //MAX = 11
# define hm 20 //hm = 20
using namespace std;
# include <time.h>
typedef int ElemType; //ElemType類型為int類型 即ElemType等價于int
# define keytype int //keytype類型為int型
#define maxsize 100
# define m 19 //m = 19
# define free 0 //free = 0
# define sucess 1 //sucess = 1
# define unsucess 0 //unsucess = 0
int size = 0; //哈希表的長度
/*定義一個名為sstable結構體數據類型 包含兩部分int *elem 和 int length */
typedef struct sstable
{
ElemType *elem;
ElemType length;
} SSTable; //SSTable 等價于 struct sstable
typedef struct hashtable
{
keytype key;
}hashtable;//hashtable 等價于 struct hashtable
/*順序表結構體定義*/
typedef struct
{
keytype key[maxsize];
int len;
}stable;
int show();
void Create(SSTable *table, int length);//創建
void Destroy(SSTable *table);//銷毀
int Search_Seq(SSTable *table, ElemType key);//查找 有返回值
/* 創建 */
void Create(SSTable **table, int length)
{
SSTable *t = (SSTable*) malloc(sizeof(SSTable));
t->elem = (ElemType*)malloc(sizeof(ElemType)*(length+1));
t->length = length;
*table = t;
}
/* 函數:判斷是否已滿 */
void FillTable(SSTable *table)
{
ElemType *t = table->elem;
srand(time(NULL));
for(int i=0; i<table->length; i++)
{
t++;
*t = 90-rand()%100;
}
}
/* 函數:銷毀 */
void Destroy(SSTable *table)
{
free(table->elem); //先保存后釋放
free(table);
}
/* 函數:顯示 */
void PrintTable(SSTable *table)
{
int i;
ElemType *t = table->elem;
for(i=0; i<table->length; i++)//進入循環,依次打印表中元素
{
t++;
printf("%d ", *t);
}
printf("\n");
}
/* 函數:查找 */
int Search_Seq(SSTable *table, ElemType key)
{
int result;
int i;
for (i=table->length; i>=1; i--)
{
if (table->elem==key)
{
result = i;
break;
}
}
return result; //將result的只返回到函數:順序查找 void printSeq()
}
/* 順序查找 */
void printSeq()
{
SSTable *table;
int r;
int n;
ElemType key;//等價于int key;
printf("請輸入元素個數:");
scanf("%d", &n);
rewind(stdin);/* 清緩沖 */
Create(&table, n); //隨機創建 n 個元素
FillTable(table); //判斷所輸入的個數 n 是否溢出
printf("您輸入的%d 個值是:", n);
PrintTable(table);
printf("請輸入關鍵字的值:");
scanf("%d", &key);
rewind(stdin);/* 清緩沖 */
printf("\n");
printf("順序查找法運行結果如下:\n\n ");
Search_Seq(table, key);
r = Search_Seq(table, key);
if(r > 0)
{
printf("關鍵字%d 在表中的位置是:%d\n", key, r);
printf("\n");
system("pause");
system("cls");
}
else
{
printf ("查找失敗,表中無此數據。\n\n");
system("pause");
system("cls");
}
}
/* 函數:冒泡排序 */
void Sort(SSTable *table )
{
int i, j;
ElemType temp;
for (i=table->length; i>=1; i--)
{
for (j=1; j<i; j++)
{
if(table->elem[j]<table->elem[j+1])
{
temp = table->elem[j];
table->elem[j] = table->elem[j+1];
table->elem[j+1] = temp;
}
}
}
}
/* 函數:二分法查找 */
int Search_Bin(SSTable *table, ElemType key)
{
int low = 1;
int high = table->length;
int result = 0;
while(low <= high)
{
int mid = (low+high)/2;
if(table->elem[mid]==key)
{
result = mid;
break;
}
else if(key<table->elem[mid])
{
low = mid+1;
}
else
{
high = mid-1;
}
}
return result;
}
/* 函數:二分法查找、排序及輸出 */
void printBin()
{
SSTable *table;
int r;
int n;
ElemType key;
printf("請輸入元素個數:");
scanf("%d", &n);
if (n<0)
{
printf("輸入有誤,請重新選擇!\n");
system("pause");
system("cls");
n = show();
system("pause");
system("cls");
printf("\n");
}
else
{
Create(&table, n);
FillTable(table);
printf("您輸入的%d 個值是:\n",n);
PrintTable(table);
printf("請輸入關鍵字的值:");
scanf("%d", &key);
rewind(stdin);/* 清緩沖 */
printf("\n");
Sort(table);
printf("數據排序后的順序如下:\n\n ");
PrintTable(table);
printf("\n");
printf("二分查找法的運行結果如下:\n\n ");
r = Search_Bin(table, key);
if( r > 0)
{
printf("關鍵字%d 在表中的位置是:%d\n", key, r);
system("pause");
system("cls");
}
else
{
printf ("查找失敗,表中無此數據。\n\n");
system("pause");
system("cls");
}
}
}
/*散列函數*/
int HashFunction(keytype key)
{
return key % (hm - 5);
}
/*創建hash表*/
void hashcreate(hashtable ht[], keytype key)
{
int index = HashFunction(key);
if(size == hm-1 || ht[index].key == key) //hash表已滿
return;
//無沖突
if(ht[index].key==0)
ht[index].key = key;
else//沖突
{
do{
index = (index + 1) % hm; //解決沖突函數
}while(ht[index].key != 0);
ht[index].key = key;
}
size++;
}
/* 函數:哈希查找 */
int hashsearch(hashtable ht[], keytype key)
{
int f = 0; //查找失敗次數
int index = HashFunction(key);
while(f <= hm)
{
if(ht[index].key == key)
return index;
else
index = (index + 1) % hm;
f++;
}
return -1;
}
/* 哈希查找 */
void hashtable()
{
int val;
printf("請輸入要建立哈希表的元素:\n");
scanf("%d", &val);
system("pause");
system("cls");
//1. 建立哈希表
//2. 創建是否成功
//3. 輸入要查找的元素
}
/* 主界面菜單 */
int show()
{
int i = -1;
printf("\n\n\n\n\n");
printf("\t\t\t***********主菜單界面***********\n");
printf("\t\t\t*** ***\n");
printf("\t\t\t*** 1. 順序查找 ***\n");
printf("\t\t\t*** 2. 二分查找 ***\n");
printf("\t\t\t*** 3. 哈希查找 ***\n");
printf("\t\t\t*** 4. 退出程序 ***\n");
printf("\t\t\t*** ***\n");
printf("\t\t\t********************************\n");
printf("\t\t\t請輸入選項(1-4):");
scanf("%d", &i);//輸入要數字選擇要使用的查找方法
return i;
}
/*建立線性表*/
stable create_s(stable r)
{
int i, j = 0, k = 1;
printf("請輸入順序表元素,要為整形,用空格分開,-99為結束標志:\n");
scanf("%d",&i);
while(i!=-99)
{
j++;
r.key[k]=i;
k++;
scanf("%d",&i);
}
r.len=j;
return r;
}
/*手動順序表查找*/
int search_s(keytype k,stable *r)
{
int j;
j=r->len;
r->key[0]=k;
while(r->key[j]!=k)
j--;
return j;
}
void search_shoudong()
{
stable a;
int i;
int k;
a = create_s(a);
while(i!=-1)
{
printf("\n輸入待查關鍵字(輸入-1結束查找):");
scanf("%d",&i);
k=search_s(i,&a);
if(i==-1)
{
getchar();
break;
}
if(k==0)
{
printf("順序表中待查元素不存在\n");
}
else
{
printf("順序表中待查元素位置是:%d",k);
printf("\n");
}
}
system("pause");
system("cls");
//1.輸入元素建立線性表
//2.判斷是否建立成功
//3.輸入查找的元素
//4.if(查找成功)
// 輸出查找的結果
// else
// 查找失敗
}
/* 主函數 */
int main(int argc, char* argv[])
{
int i, choice;
system("color 5");
do
{
i = show();
switch(i)
{
case 1:
printf("\n");
printf("*********************************** 順序查找 *********************************** \n");
printf("查找的方法:1. 隨即查找 2. 手動輸入查找 \n");
scanf("%d", &choice);
if(1 == choice)
printSeq();//隨機順序查找法
else
{
search_shoudong();
}
break;//跳出循環}
case 2:
printf("\n");
printf("*********************************** 二分查找 *********************************** \n");
printBin();//二分查找法
break; //跳出循環
case 3:
printf("\n");
printf("*********************************** 哈希查找 *********************************** \n");
hashtable();//哈希查找
break; //跳出循環
case 4:
printf("\n");
printf("\n歡迎使用該系統,再見!\n");
system("pause");
exit(0);
default:
printf("輸入選項有誤,請重新輸入!\n");
rewind(stdin);//等價于fflush(stdin);清緩沖 不然輸入垃圾字符就陷入了死循環
system("pause");
system("cls");
break;
}
}while(i!=4);
return 0;
}
|
|







 QQ好友和群
QQ好友和群 QQ空間
QQ空間 騰訊微博
騰訊微博 騰訊朋友
騰訊朋友 收藏
收藏 淘帖
淘帖 頂
頂 踩
踩

