熱門(mén): 51單片機(jī) | 24小時(shí)必答區(qū) | 單片機(jī)教程 | 單片機(jī)DIY制作 | STM32 | Cortex M3 | 模數(shù)電子 | 電子DIY制作 | 音響/功放 | 拆機(jī)樂(lè)園 | Arduino | 嵌入式OS | 程序設(shè)計(jì)
熱門(mén): 51單片機(jī) | 24小時(shí)必答區(qū) | 單片機(jī)教程 | 單片機(jī)DIY制作 | STM32 | Cortex M3 | 模數(shù)電子 | 電子DIY制作 | 音響/功放 | 拆機(jī)樂(lè)園 | Arduino | 嵌入式OS | 程序設(shè)計(jì)
|
2503| 0
|
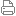



Hadoop權(quán)威指南:大數(shù)據(jù)的存儲(chǔ)與分析(第4版)簡(jiǎn)介 |
| ||
Powered by 單片機(jī)教程網(wǎng)





 QQ好友和群
QQ好友和群 QQ空間
QQ空間 騰訊微博
騰訊微博 騰訊朋友
騰訊朋友 收藏
收藏 淘帖
淘帖 頂
頂 踩
踩
