標題: 創龍帶您解密TI、Xilinx異構多核SoC處理器核間通訊 [打印本頁]
作者: Tronlong 時間: 2020-3-25 14:48
標題: 創龍帶您解密TI、Xilinx異構多核SoC處理器核間通訊
一、什么是異構多核SoC處理器
顧名思義,單顆芯片內集成多個不同架構處理單元核心的SoC處理器,我們稱之為異構多核SoC處理器,比如:
- TI的OMAP-L138(DSP C674x + ARM9)、AM5708(DSP C66x + ARM Cortex-A15)SoC處理器等;
- Xilinx的ZYNQ(ARM Cortex-A9 + Artix-7/Kintex-7可編程邏輯架構)SoC處理器等。
二、異構多核SoC處理器有什么優勢
相對于單核處理器,異構多核SoC處理器能帶來性能、成本、功耗、尺寸等更多的組合優勢,不同架構間各司其職,各自發揮原本架構獨特的優勢。比如:
- ARM廉價、耗能低,擅長進行控制操作和多媒體顯示;
- DSP天生為數字信號處理而生,擅長進行專用算法運算;
- FPGA擅長高速、多通道數據采集和信號傳輸。
同時,異構多核SoC處理器核間通過各種通信方式,快速進行數據的傳輸和共享,可完美實現1+1>2的效果。
三、常見核間通信方式
要充分發揮異構多核SoC處理器的性能,除開半導體廠家對芯片的硬件封裝外,關鍵點還在于核間通信的軟硬件機制設計,下面介紹幾種在TI、Xilinx異構多核SoC處理器上常見的核間通信方式。
OpenCL(全稱Open Computing Language,開放運算語言)是第一個面向異構系統通用目的并行編程的開放式、免費標準,也是一個統一的編程環境,便于軟件開發人員編寫高效輕便的代碼,而且廣泛適用于多核心處理器(CPU)、圖形處理器(GPU)、Cell類型架構以及數字信號處理器(DSP)等其他并行處理器,在能源電力、軌道交通、工業自動化、醫療、通信、軍工等應用領域都有廣闊的發展前景。
在異構多核SoC處理器上,OpenCL將其中一個可編程內核視為主機,將其他內核視為設備。在主機上運行的應用程序(即主機程序)管理設備上的代碼(內核)的執行,并且還負責使數據可用于設備。設備由一個或多個計算單元組成。比如,在TI AM5728異構多核SoC處理器中,每個C66x DSP都是一個計算單元。

OpenCL運行時,一般包含如下兩個組件:
- 主機程序創建和提交內核以供執行的API。
- 用于表達內核的跨平臺語言。
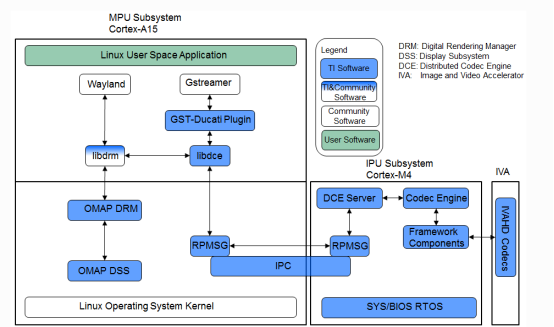
2.DCE
DCE(Distributed Codec Engine)分布式編解碼器引擎,是TI基于AM57x異構多核SoC處理器的視頻處理框架,提供的完整Gstreamer插件框架。
DCE由三部分硬件模塊組成,分別為MPU核心、IPU2核心以及IVA-HD硬件加速器,其主要功能如下:
MPU:基于ARM用戶空間Gstreamer應用,控制libdce模塊。libdce模塊在ARM RPMSG框架上實現與IPU2的IPC通信。
IPU2:構建DCE server,基于RPMSG框架與ARM實現通信,使用編解碼器引擎和幀組件控制IVA-HD加速器。
IVA-HD:實現視頻/圖像編解碼的硬件加速器。
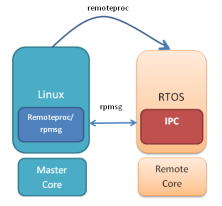
3.IPC
IPC(Inter-Processor Communication)是一組旨在促進進程間通信的模塊。通信包括消息傳遞、流和鏈接列表。這些模塊提供的服務和功能可用于異構多核SoC處理器中ARM和DSP核心之間的通信。
如下為TI異構多核SoC處理器常用的核間通信方式的優缺點比較:
方式 | 優點 | 缺點 |
| - 易于在設備之間移植
- 無需了解內存架構
- 無需擔心MPAX和MMU
- 無需擔心一致性
- 無需在ARM和DSP之間構建/配置/使用IPC
- 無需成為DSP代碼、架構或優化方面的專家
| |
| - 加速多媒體編解碼處理
- 在與Gstreamer和TI Gstreamer插件連接時簡化多媒體應用程序的開發
| - 不適合非編解碼算法
- 需要努力添加新的編解碼算法
- 需要DSP編程知識
|
| - 完全控制DSP配置
- 能夠進行DSP代碼優化
- 在多個TI平臺上支持相同的API
| - 需要了解內存架構
- 需要了解DSP配置和編程
- 僅限于小型消息(小于512字節)
- TI專有API
|
4.AXI
AXI(Advanced eXtensible Interface)是由ARM公司提出的一種總線協議,Xilinx從6系列的FPGA開始對AXI總線提供支持,目前使用AXI4版本。

ZYNQ有三種AXI總線:
(A)AXI4:(For high-performance memory-mapped requirements.)主要面向高性能地址映射通信的需求,是面向地址映射的接口,允許最大256輪的數據突發傳輸。
(B)AXI4-Lite:(For simple, low-throughput memory-mapped communication.)是一個輕量級的地址映射單次傳輸接口,占用很少的邏輯單元。
(C)AXI4-Stream:(For high-speed streaming data.)面向高速流數據傳輸,去掉了地址項,允許無限制的數據突發傳輸規模。
AXI協議的制定是要建立在總線構成之上的。因此,AXI4、AXI4-Lite、AXI4-Stream都是AXI4協議。AXI總線協議的兩端可以分為分為主(master)、從(slave)兩端,他們之間一般需要通過一個AXI Interconnect相連接,作用是提供將一個或多個AXI主設備連接到一個或多個AXI從設備的一種交換機制。
AXI Interconnect的主要作用是:當存在多個主機以及從機器時,AXIInterconnect負責將它們聯系并管理起來。由于AXI支持亂序發送,亂序發送需要主機的ID信號支撐,而不同的主機發送的ID可能相同,而AXI Interconnect解決了這一問題,他會對不同主機的ID信號進行處理讓ID變得唯一。
AXI協議將讀地址通道、讀數據通道、寫地址通道、寫數據通道、寫響應通道分開,各自通道都有自己的握手協議。每個通道互不干擾卻又彼此依賴。這是AXI高效的原因之一。
四、IPC核間通信開發
下面以創龍AM57x(AM5728/AM5708)評估板源碼為例,講解IPC核間通信開發。
- RTOS Processor-SDK 04.03.00.05。
- Linux-4.9.65/Linux-RT-4.9.65內核。
- IPC開發包版本:3.47.01.00。
IPC(Inter-Processor Communication)提供了一個與處理器無關的API,可用于多處理核心環境中的核間通信、與同一處理核心上的其他線程的通信(進程間)和與外圍設備(設備間)的通信。IPC定義了以下幾種通信組件,如下表所示,這些通信組件的接口都有以下幾個共同點:
- 所有IPC通信組件的接口都由系統規范化命名。
- 在HLOS端,所有IPC接口需要使用_setup()來初始化,使用_destroy()來銷毀相應的IPC Module;部分初始化還需要提供配置接口_config()。
- 所有的實例化都需要使用_create()來創建,使用_delete()來刪除。
- 在更深層次使用IPC時需要用_open()來獲取handle,在結束使用IPC時需要用_close()來回收handle。
- IPC的配置多數都是在SYS/BIOS下完成配置的,對于支持XDC配置的則可以使用靜態配置方法。
- 每個IPC模塊都支持trace信息用于調試,而且支持不同的trace等級。
- 部分IPCs提供了專門的APIs來用于提取分析信息。
本小節主要演示MessageQ通信組件的運用。
2.MessageQ機制
- 支持結構化發送和接收可變長度消息。
- 一個MessageQ都將有一個讀者,多個編寫者。
- 既可用于同構和異構多處理器消息傳遞,也可用于線程之間的單處理器消息傳遞。
- 功能強大,簡單易用。

2.MessageQ機制代碼解釋
MessageQ的傳輸,主要區分為發送者,跟接收者,下述為常用API的功能描述:
- MessageQ_Handle MessageQ_create (String name, MessageQ_Params *params):創建消息隊列,創建隊列名稱將成為后面MessageQ_open的依據。
- Int MessageQ_open(String name , MessageQ_QueueId * queueId):打開創建的消息隊列,獲取隊列ID值(ID值應為唯一值,所以創建消息隊列時名稱要唯一)。
- MessageQ_Msg MessageQ_alloc(UInt16 heapId, UInt32 size):申請消息空間,從heap中申請,所以需要先打開heap獲取heapID,消息由MessageQ_Msg結構體長度規定。
- MessageQ_registerHeap(HeapBufMP_Handle_upCast(heapHandle),HEAPID):注冊堆,分配heapID給這個堆,作為一個唯一標識符。
- Int MessageQ_put(MessageQ_QueueId queueId, MessageQ_Msg msg):發送消息到queueId對應的消息隊列。
- Int MessageQ_get(MessageQ_Handle handle,MessageQ_Msg *msg,UInt timeout):從消息隊列中接收消息。
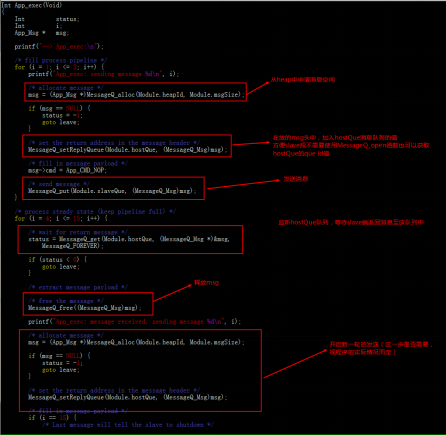
- MessageQ_free(MessageQ_Msg *msg):釋放msg空間,注意不用的消息空間需要釋放,不然會導致內存問題。以ex02_messageq例程為例,說明MessageQ機制的使用過程:
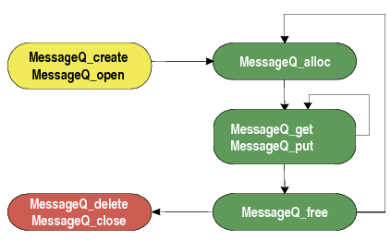
例程運行流程圖如下:
結合實際代碼分析上述流程:
ARM:
a)創建host消息隊列,打開slave消息隊列。
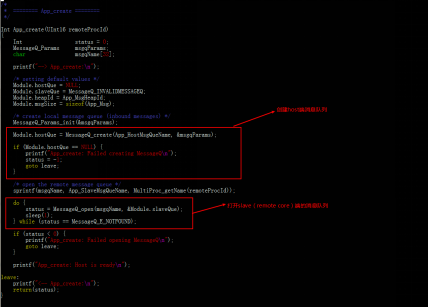
b)發送消息至slave消息隊列,監聽host消息隊列,等待返回信息 。
c)發送shutdown消息至slave隊列。
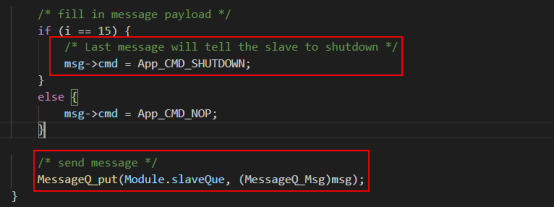
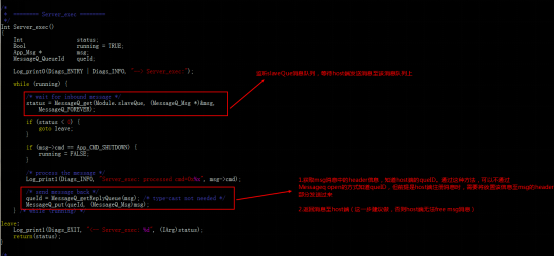
DSP:
a)創建slave消息隊列。

b)監聽slave消息隊列,并返回消息至host端。
c)接收shutdown消息,停止任務。

3.內存訪問與地址映射問題。
首先,對于DSP/IPU子系統和L3互連之間的存儲器管理單元(MMU),都用于將虛擬地址(即DSP/IPU子系統所查看的地址)轉換為物理地址(即從L3互連中看到的地址)。
DSP:MMU0用于DSP內核,MMU1用于本地EDMA。
IPU:IPUx_UNICACHE_MMU用于一級映射,IPUx_MMU用于二級映射。
rsc_table_dspx.h,rsc_table_ipux.h資源表中,配置了DSP/IPU子系統的映射關系,在固件啟動前,該映射關系將會寫入寄存器,完成映射過程。
物理地址跟虛擬地址之間的映射關系查看:
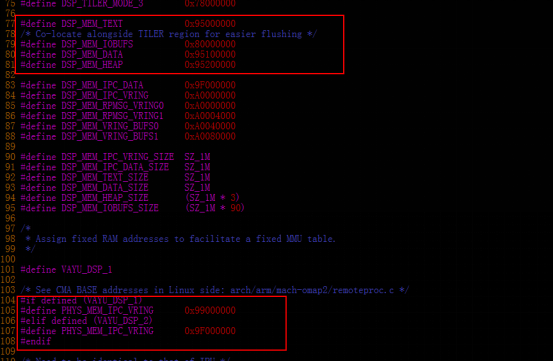
DSP1:(默認配置mmu1的配置與mmu2的配置是一樣的)
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable
cat /sys/kernel/debug/omap_iommu/40d02000.mmu/pagetable
DSP2:(默認配置mmu1的配置與mmu2的配置是一樣的)
cat /sys/kernel/debug/omap_iommu/41501000.mmu/pagetable
cat /sys/kernel/debug/omap_iommu/41502000.mmu/pagetable
IPU1:
cat /sys/kernel/debug/omap_iommu/58882000.mmu/pagetable
IPU2:
cat /sys/kernel/debug/omap_iommu/55082000.mmu/pagetable
Resource_physToVirt(UInt32pa,UInt32*da);
Resource_virtToPhys(UInt32da,UInt32*pa);
CMA內存,用于存放IPC程序的堆棧,代碼以及數據段。
dts文件中,預留了幾段空間作為從核的段空間(DDR空間):

IPC-demo/shared/config.bld:用于配置段空間的起始地址,以及段大小。
以DSP1為例,說明DMA中的內存映射關系:
通過系統中查看虛擬地址表,左邊da(device address)對應的為虛擬地址,右邊對應的為物理地址,那么虛擬地址的0x95000000的地址映射到的應該是0x99100002的物理地址。
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable
2.共享內存
共享內存:其實是一塊“大家”都可以訪問的內存。
CMEM是一個內核驅動(ARM),是為了分配一個或多個block(連續的內存分配),更好地去管理內存的申請(一個或多個連續的內存分配block),釋放以及內存碎片的回收。
CMEM內存:由linux預留,CMEM驅動管理的一段空間。
arch/arm/boot/dts/am57xx-evm-cmem.dtsi中定義了CMEM,并預留了空間出來作為共享內存(DDR & OCMC空間)。
cmem{}中最大分配的block數量為4個,cmem-buf-pools的數量沒有限制。
實際使用上,DSP與IPU訪問的都是虛擬地址,所以還要完成虛擬地址到物理地址的映射關系。
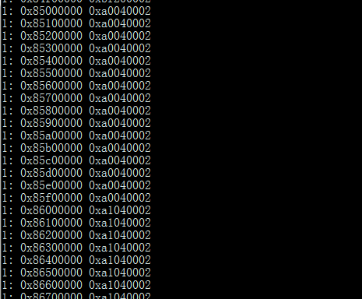
dsp1/rsc_table_dsp1.h定義了虛擬地址到物理地址的映射表,虛擬地址(0x85000000)到物理地址0xA0000000的映射,那么在DSP端訪問0x85000000的地址時,實際上通過映射訪問的物理地址應是0xA0000000。
cat /sys/kernel/debug/omap_iommu/40d01000.mmu/pagetable
實際應用:
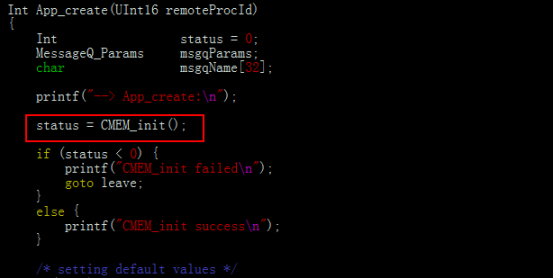
a)初始化cmem。
b)申請內存空間,并轉換為物理地址(msg傳輸的時候傳輸的是物理地址,否則傳輸虛擬地址有不確定性)。
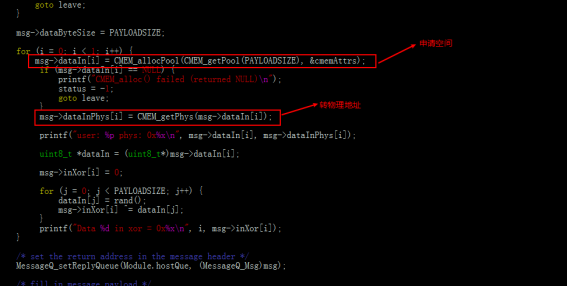
DSP端的處理:接收物理地址,轉換為虛擬地址進行操作,發送操作完成的結果。這里DSP需要將地址返回給ARM的話,那應該將虛擬地址轉換為物理地址,再傳給ARM端。

作者: Flq6 時間: 2020-11-17 16:18
DSP1與DSP2的rsc_table_dsp1.h,rsc_table_dsp2.h是一樣的,那他們訪問的內存的時候不會沖突嗎?
ipu1與ipu2的rsc_table_ipux.1、rsc_table_ipu2.h是一樣的,不會沖突嗎?
| 歡迎光臨 (http://www.raoushi.com/bbs/) |
Powered by Discuz! X3.1 |